Revolutionize Video Creation: Wan2.1 Now Supported in ComfyUI
Get ready for a big new wave of open video model releases! Today comfyui excited to share ComfyUI’s native support for Wan2.1, the latest video generation model in town!
Wan2.1 is a series of 4 video generation models, including:
Text-to-video 14B: Supports both 480P and 720P
Image-to-video 14B 720P: Supports 720P
Image-to-video 14B 480P: Supports 480P
Text-to-video 1.3B: Supports 480P
Highlights of the Wan2.1 Family
Supports Consumer-grade GPUs: The T2V-1.3B model requires only 8.19 GB VRAM, making it compatible with almost all consumer-grade GPUs. It can generate a 5-second 480P video on an RTX 4090 in about 4 minutes (without quantization).
Multiple Tasks: Wan2.1 excels in Text-to-Video, Image-to-Video, Video Editing, Text-to-Image, and Video-to-Audio, advancing the field of video generation.
Visual Text Generation: Wan2.1 is the first video model capable of generating both Chinese and English text.
Powerful Video VAE: Wan-VAE delivers exceptional efficiency and performance, encoding and decoding 1080P videos of any length while preserving temporal information, making it an ideal foundation for video and image generation.
Get Started in ComfyUI
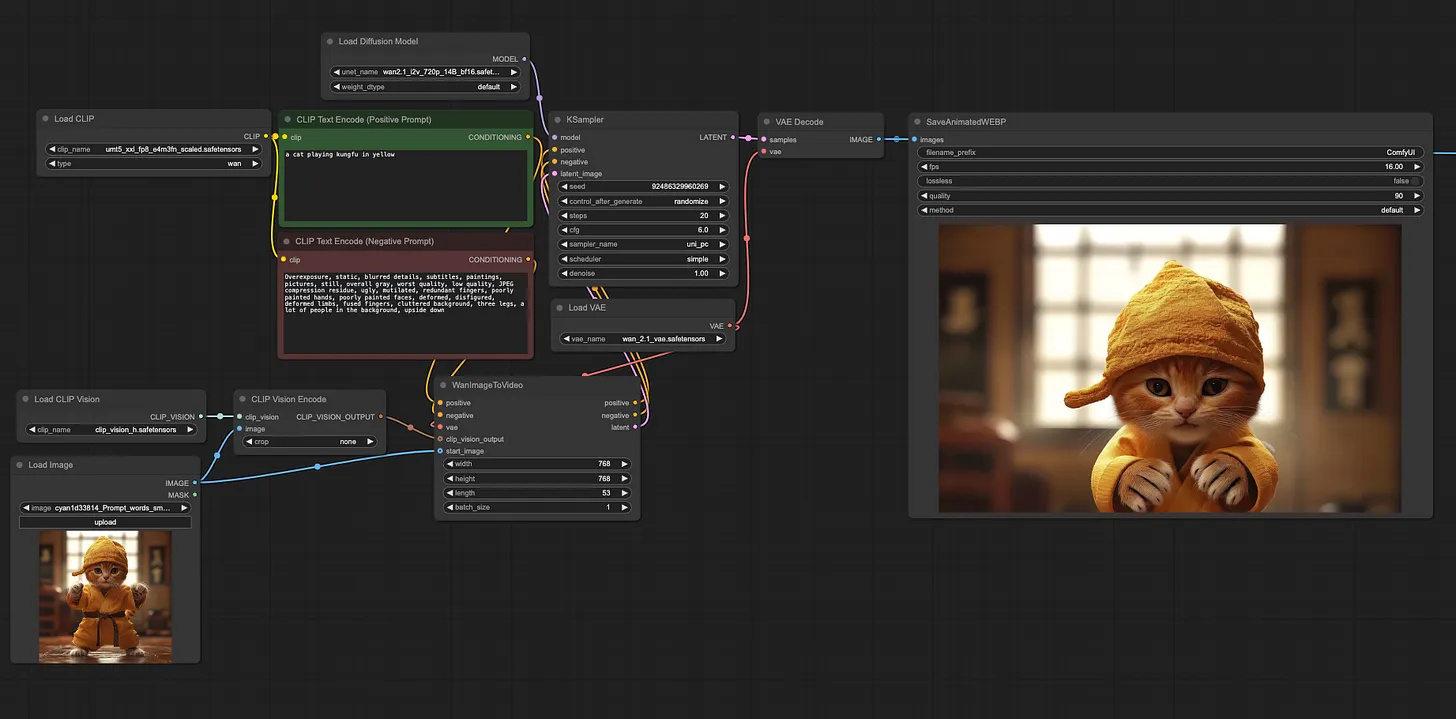
Update ComfyUI to the latest
Download the following 4 files:
Choose one of the diffusion models → Place in
ComfyUI/models/diffusion_modelsumt5_xxl_fp8_e4m3fn_scaled.safetensors → Place in
ComfyUI/models/text_encodersclip_vision_h.safetensors → Place in
ComfyUI/models/clip_visionwan_2.1_vae.safetensors → Place in
ComfyUI/models/vae
Use the example workflows or click the example videos below
Examples
Image-to-video 14B 720P Workflow



Image-to-video 14B 480P Workflow


Text-to-video 14B 720P Workflow


Text-to-video 1.3B 480P Workflow

Note
To run the 480p/720p image-to-video model with umt5_xxl_fp8_e4m3fn_scaled.safetensors, you need ~40GB VRAM.
The 1.3B text-to-video model takes around 15GB VRAM.
Enjoy creation!