Unlocking the Power of Multimodal AI: Jieyue Xingchen's Step-Video-TI2V Model Revolutionizes Image-to-Video Generation
In February this year, Jieyue Xingchen open-sourced two models from its Step series—Step-Video-T2V, a video generation model, and Step-Audio, a speech model, contributing to the open-source community with its multimodal capabilities. On March 20, Jieyue Xingchen continued to open-source the image-to-video model—Step-Video-TI2V. This model is based on the 30B parameter Step-Video-T2V and supports generating 102 frames, 5-second, 540P resolution videos. It features two core capabilities: controllable motion amplitude and controllable camera movement, while also having some built-in special effects generation abilities. Compared to other existing open-source image-to-video models, Step-Video-TI2V not only offers a higher upper limit for research in the field due to its parameter scale, but also its controllable motion amplitude ability balances the dynamic and stable results of image-to-video generation, providing creators with more flexible choices.
At the same time, Step-Video-TI2V has been adapted for Huawei Ascend computing platforms and is now available on the Modelers community (Modelers), so feel free to try it out. Torch Ascend adaptation link: https://modelers.cn/models/StepFun/Step-Video-TI2V-NPUMindIE. Adaptation link: https://modelers.cn/models/MindIE/StepVideo-TI2V.
Two Major Technical Highlights: How Step-Video-TI2V Was Made
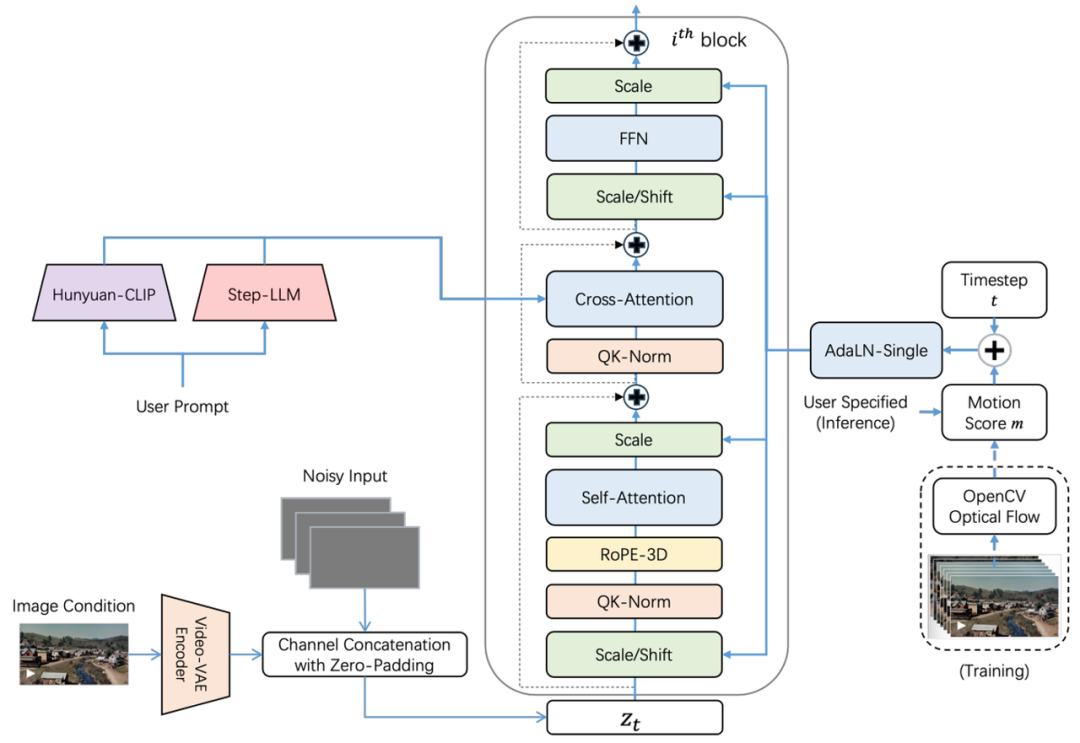
Compared to the text-to-video model Step-Video-T2V, the newly open-sourced Step-Video-TI2V has undergone two key optimizations for the image-to-video task:
Introducing Image Conditioning for Improved Consistency: To better understand the input image, the model uses a more direct and efficient method instead of the traditional cross-attention method. The vector representation of the image is directly concatenated with the vector representation of the first frame in the DiT, which ensures the generated video aligns more consistently with the original image.
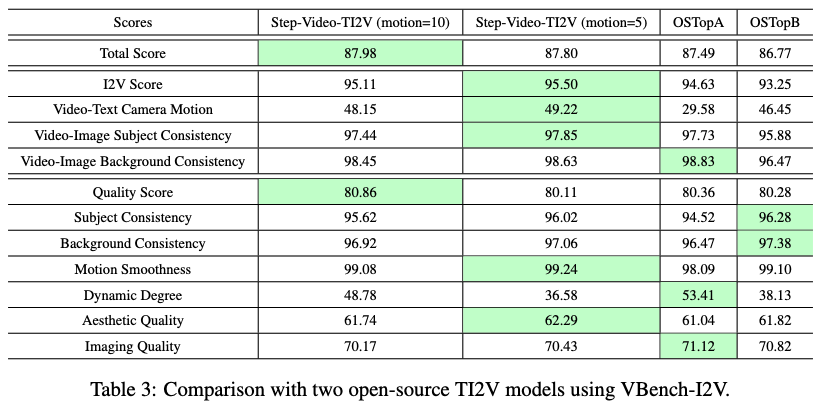
Introducing Motion Amplitude Control for Greater User Flexibility: During training, Step-Video-TI2V integrates dynamic scoring information via the AdaLN module, specifically training the model to learn the dynamic degree of video content. Users can easily specify different motion levels (motion = 2, 5, 10) to precisely control the video's dynamic amplitude, balancing the video's dynamism, stability, and consistency. Additionally, in terms of data optimization, specific annotations have been made for subject movements and camera actions, giving Step-Video-TI2V an advantage in subject dynamism and camera movement effects. The model achieved state-of-the-art performance in the VBench-I2V benchmark test, validating the dynamic scoring's ability to control video stability and consistency.
Core Features
Controllable Motion Amplitude: Switch Between Dynamic & Stable
Step-Video-TI2V supports controlling the "motion amplitude" of the video, balancing the motion and stability of image-to-video content. Whether for static, stable scenes or high dynamic action sequences, it meets the needs of creators.
The motion amplitude (motion) values range from 2, 5, 10 to 20, with larger values resulting in greater dynamism. It is recommended to use values such as 2, 5, or 10 when generating videos.Multiple Camera Movement Controls
In addition to controlling the movement of subjects within the frame, Step-Video-TI2V supports the understanding of various camera movements, allowing precise control over the camera motion in generated videos. This enables the production of cinematic-level camera effects, from basic push, pull, tilt, and pan to more complex, movie-grade camera movements.Best Results for Animation
Step-Video-TI2V performs exceptionally well in animation-related tasks, making it particularly suitable for applications such as animation creation and short video production.Support for Multiple Video Sizes
Step-Video-TI2V supports generating image-to-video content in multiple aspect ratios. Whether it’s a wide-screen landscape view, a vertical immersive experience, or a square vintage style, it can easily handle them. Users can freely select the image size based on different creative needs and platform specifications, without worrying about distortion or aspect ratio issues.
Now Available for Experience
In addition, Step-Video-TI2V now has some initial special effects generation capabilities. In the future, the model’s special effects potential will be continuously unlocked using technologies like LoRA, so stay tuned for more exciting developments!
Model and technical report links are available for further details:
GitHub: https://github.com/stepfun-ai/Step-Video-TI2V
GitHub-ComfyUI: https://github.com/stepfun-ai/ComfyUI-StepVideo
Technical report: https://arxiv.org/abs/2503.11251