革新视频创作:ComfyUI现已支持Wan2.1
准备好迎接一波全新的开源视频模型发布浪潮吧!今天,ComfyUI 地宣布 ComfyUI 已经原生支持 Wan2.1,这是最新的视频生成模型!Wan2.1 是一系列 4 个视频生成模型,包括:
Text-to-video 14B:支持 480P 和 720P
Image-to-video 14B 720P:支持 720P
Image-to-video 14B 480P:支持 480P
Text-to-video 1.3B:支持 480P
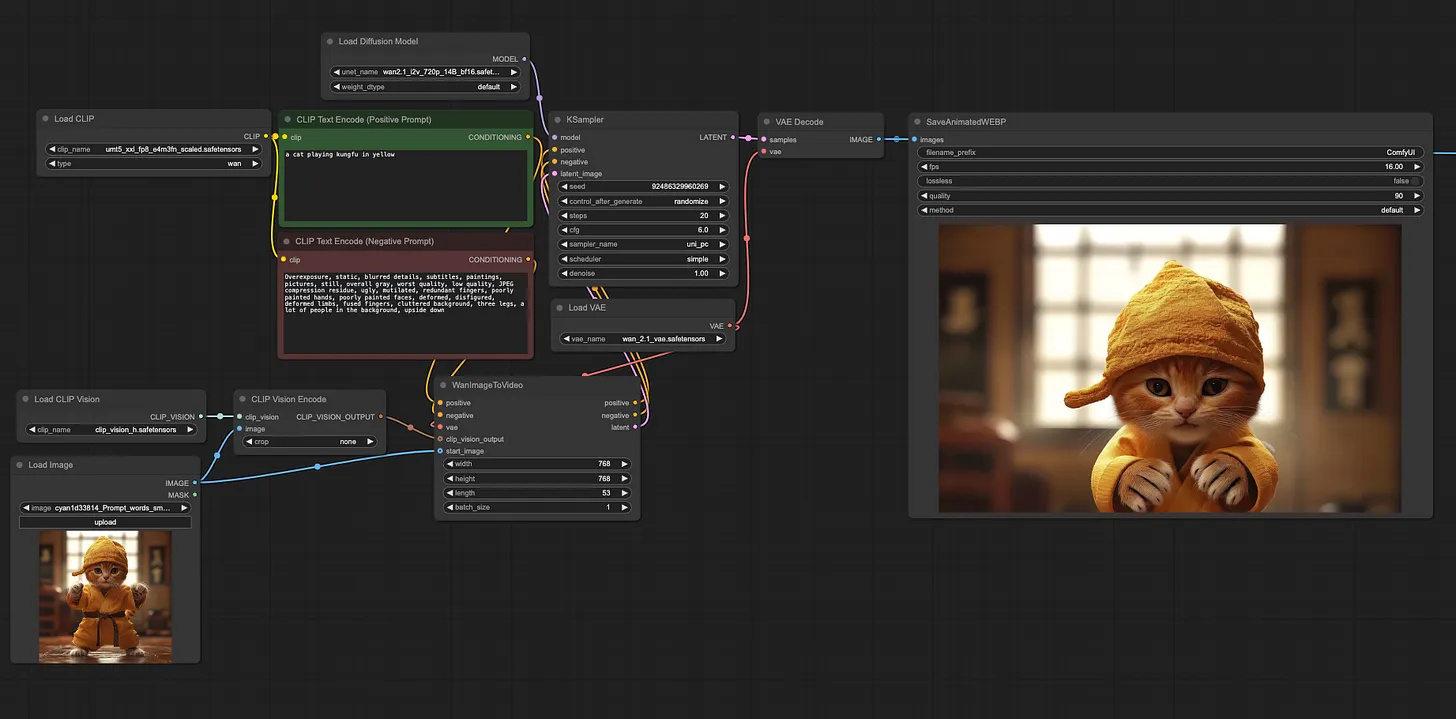
Wan2.1 家族的亮点
支持消费级 GPU:T2V-1.3B 模型仅需 8.19 GB 显存,兼容几乎所有消费级 GPU。在 RTX 4090 上,它可以在约 4 分钟内生成一段 5 秒的 480P 视频(未量化)。
多任务支持:Wan2.1 在文本到视频、图像到视频、视频编辑、文本到图像以及视频到音频等任务中表现出色,推动了视频生成领域的发展。
视觉文本生成:Wan2.1 是首个能够生成中文和英文文本的视频模型。
强大的视频 VAE:Wan-VAE 在编码和解码任意长度的 1080P 视频时,展现了卓越的效率和性能,同时保留了时间信息,成为视频和图像生成的理想基础。
在 ComfyUI 中启程
将 ComfyUI 更新到最新版本。
下载以下 4 个文件:
选择一个扩散模型 → 放置在 ComfyUI/models/diffusion_model
umt5_xxl_fp8_e4m3fn_scaled.safetensors → 放置在 ComfyUI/models/text_encoder
clip_vision_h.safetensors → 放置在 ComfyUI/models/clip_vision
wan_2.1_vae.safetensors → 放置在 ComfyUI/models/vae
使用示例工作流,或点击下面的示例视频。
示例
Image-to-video 14B 720P Workflow



Image-to-video 14B 480P Workflow


Text-to-video 14B 720P Workflow


Text-to-video 1.3B 480P Workflow
注意事项
运行 480p/720p 图像到视频模型时,使用 umt5_xxl_fp8_e4m3fn_scaled.safetensors 需要约 40GB 显存。
1.3B 文本到视频模型需要约 15GB 显存。
尽情创作吧!