Mastering Conditional Image Synthesis: A Comprehensive Workflow
1. Workflow Overview
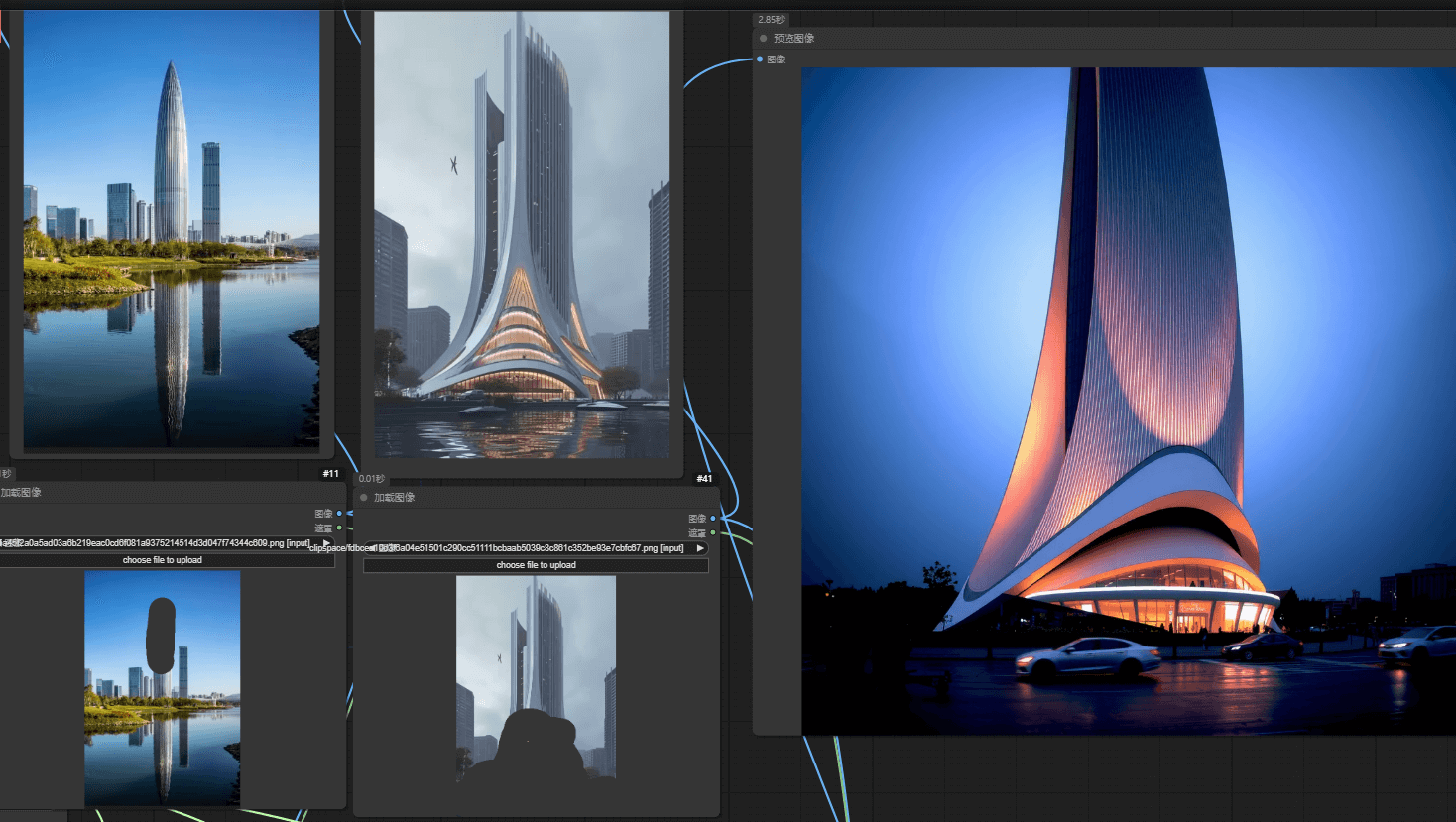
This workflow is designed for multi-element fusion, combining reference images, style models, and conditional controls. Key features:
Multi-Image Fusion: 3 image+mask inputs via
ReduxAdvancednodes.Advanced Control:
FluxGuidanceadjusts generation strength (default=3.5).Custom Models: Independent UNet, CLIP, and VAE loading.
Core Models:
UNet:
flux1-dev.sft(FP8 optimized)CLIP: Dual encoders (
ViT-L-14-TEXT-detail+t5xxl_fp8)Style Model:
flux1-redux-dev.safetensorsVAE:
ae.sft
2. Node Breakdown
Node | Function | Installation |
|---|---|---|
| Fuses images/styles/masks | Manual install ( |
| Loads dual CLIP text encoders | Built-in |
| Loads style transfer model | Requires model file |
| Optimizes generation details | Built-in |
| Controls conditioning strength | Requires |
Dependencies:
Models:
Style Model:
flux1-redux-dev.safetensorsCLIP Vision:
google--siglip-so400m-patch14-384/model.safetensors
Plugins:
Redux Plugin: For image fusion (GitHub).Flux Plugin: Advanced conditioning.
3. Workflow Groups
Input Group:
Images: 3 sets of images+masks (via
LoadImage).Text: Dual CLIP encoders for prompts.
Fusion Group:
ReduxAdvanced Nodes:
Input: Image+Mask+Style Model+CLIP Vision.
Output: Fused conditioning.
Generation Group:
Sampling: Euler, 30 steps, CFG=1.
Output: 1024x1024 image (decoded by
VAEDecode).
4. Inputs & Outputs
Inputs:
Images: ≥1 reference image (3 recommended with masks).
Prompts: Positive/negative text via
CLIPTextEncode.Strength:
FluxGuidanceparameter (default=3.5).
Output: HD image (1024x1024) saved to
ComfyUI/output.
5. Notes
VRAM: ≥12GB GPU required for multi-image fusion.
Model Compatibility: Ensure
flux1-redux-dev.safetensorsmatches UNet version.Troubleshooting:
Missing Node: InstallRedux/Fluxplugins.Image Size Mismatch: Uniform resolution required.
Optimization: Use FP8 models (e.g.,
t5xxl_fp8) to reduce VRAM usage.